数据来源的一个重要途径就是爬虫,有了数据才能进行后续的数据分析和办公自动化。比如本期主题想找一份Python开发类工作,可以在BOSS直聘网上查找,薪酬在15-40k之间比比皆是。这种垂直类渠道网站比较有针对性,可以很快找到目标岗位的职位,分类也比较细。具体来看下实现方式。
1、相关库的导入
import time
import csv
from selenium import webdriver
from lxml import etree
import random2、计算总页数
try:
next_page_tag = driver.find_element_by_xpath("//a[@class='next']")
next_page_tag.click()
flag = True
time.sleep(3)
except:
flag = False
print("如果没有找到,这里可以认为到了最后一页")3、匹配职位
html = etree.HTML(page_source)
info_links = html.xpath("//div[@class='job-list']/ul/li")
print(info_links)
for link in info_links:
name = link.xpath(".//span[@class='job-name']/a/text()")
print(name)4、最终结果
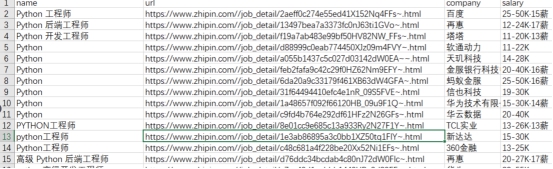
本章目标实现抓取“Python”的职位薪酬,并保存到CSV文件中。现已实现,大家如果有类似需求,可以自行尝试学习下哦~
转载自:python学习网 https://www.py.cn/




发表评论
还没有评论,快来抢沙发吧!